Ma már nyugodtan kimondhatjuk, hogy túlságosan optimisták voltak azok a becslések, amelyek 15 éve azt vetítették előre, hogy mostanra már teljesen önvezető autókat használhatunk majd. Ennek oka azonban nem az, hogy ez technikailag nem kivitelezhető, hanem az, hogy számolni kell egy állandó változóval, az emberrel! Ennek a megoldhatatlannak tűnő képletnek a megtalálásában segítenek a gráf neurális hálózatok.
Szükség van egy új megközelítésre, mert egészen addig, amíg párhuzamosan közlekednek ember által irányított és önvezető járművek, az emberi tényező kihívást jelent majd. Ráadásul nem csak a kormány mögött, mert a gyalogosok, sőt, akár a parkoló járművek is okozhatnak nehéz pillanatokat. Hogy milyen új fejlesztési módszerekre van szükség arra az önvezető rendszerek egy speciális problémájával foglalkozó budapesti mérnökcsapat segítségével kaphatunk rálátást a következőkben.
Új formátum
Ezt a bejegyzést akár meg is hallgathatod Júlia segítségével! Kattints a lejátszásra és hallgasd meg blogbejegyzésünket akár utazás, akár főzés, akár sportolás közben!
A négyes szinttől már komoly feladatok jönnek
Régóta nem titok, hogy az igazi problémát az a városi környezet jelenti az önvezető rendszereknek, pont az, ahol a legnagyobb hasznukat vennénk. Éppen ezért az új fejlesztési aspektus az ilyen környezetre fókuszál. A cél pedig az, hogy az új, tanuló algoritmusok segítségével kezelhetőek legyenek az olyan szituációk, mint a megváltozott forgalmi rend, a besorolás vagy épp a sávszűkület.

A négyes szintű önvezetéstől szembesülünk hatalmas kihívásokkal
Az új módszer – hasonlóan a korábbi tanulásra képes algoritmusokhoz – adat alapú tanítást használ, de a forrás már nem közvetlenül a szenzor nyers adata, hanem azok előre feldolgozott és világmodellekké egységesített halmaza. Ez azt jelenti, hogy például az autók pozícióval, sebességgel és minden egyéb felismert és detektált tulajdonsággal felkerülnek egy előre kimért, centiméter pontosságú térképre (HD map) és a mérnököknek ezeknek az objektumoknak a jövőbeli várható viselkedését, jelenbéli szándékát kell meghatározniuk.
Nem mindegy kit, hogyan kezelünk
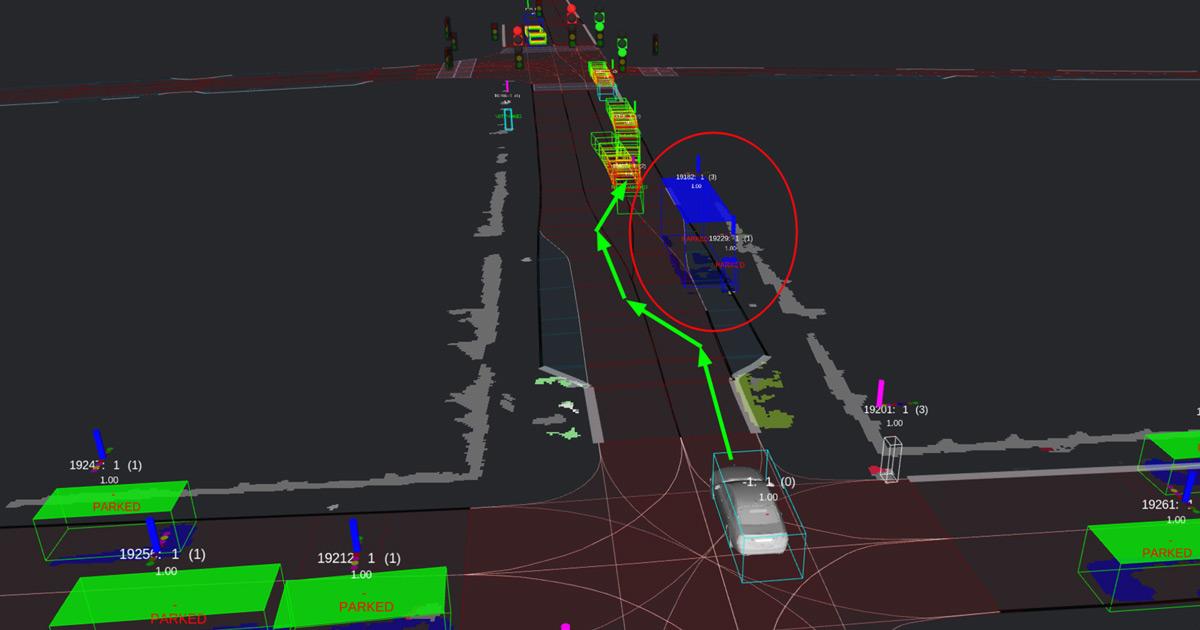
Hogyan azonosítsuk egy többsávos úton a párhuzamosan parkoló és a jobbra kanyarodásra várakozó autókat? Kit kerülhetünk ki és kit nem? Ez már része annak az emberi tényezőnek, ami miatt megkerülhetetlenné vált a mesterséges intelligencia használata az önvezető autóknál. Ez a fajta összetettség már sokkal inkább hasonlít az emberi agy működésére, mint egy egyszerű gépi tanulásra. Hol válik el élesen a két módszer, ha eredményességi szempontból vizsgáljuk?
Talán meglepő, de az elvárt végeredmény szempontjából nincs lényeges különbség. Mivel a tanító adatokat emberek címkézik, így a rendszer lehet olyan jó, mint maga az ember. Ehhez persze több adatra van szüksége annál a modellnek, mint ami most rendelkezésére áll. Jelenleg csak a mérnökök által meghatározott származtatott adatokat látja: a sebességet, a pozíciót, a határoló keretet, illetve a térkép sávokra, közlekedési táblákra és lámpákra vonatkozó információit.
Drágább is az összetett rendszer?
A rövid válasz az, hogy igen, de a helyzet összességében közel sem ilyen egyszerű. A szabály alapú megközelítésnél szinte nincs is tanítás, csak a paramétereket kell hangolni. A gépi tanulás minden esetben drágább, ebben az esetben különösen. Az adatvezérelt megközelítés előnye ugyanakkor abban rejlik, hogy a kész tanító rendszer további adatok felvételével automatikusan javítható. Nincs szükség minden egyes felmerülő probléma külön analizálására és vizsgálatára.
Döntések és azok következményei
Ez az a pillanat, amikor talán kijelenthetjük: az új módszer gyakorlatilag egyfajta jóslás. És erre nem csak a városban lehet szükség. Egy autópályás sávváltás, vagy besorolás is igen nehezen algoritmizálható. Ilyen feladatok esetében is hatékony az új módszer, sőt, ha csak az adaptív sebességszabályzó működéséhez szükséges paraméterezést vesszük figyelembe, akkor az ottani viselkedés megjóslása kapcsán is hatékony.

Többsávos utakon és autópályákon akár a sávváltás is komoly kihívásokat jelenthet, hiszen a rendszernek számolnia kell a többi közlekedő viselkedésével
Teljesen új szintre azonban a változó körülmények között emelkedhet az eddigi rendszerekkel szemben. Azt viszont túlzás lenne kijelenteni, hogy a modell döntéseket hoz. A predikciók eredményét a tervező modul dolgozza fel és tulajdonképpen a döntéseket is ő hozza. Az adat alapú megközelítés képes lehet arra, hogy váratlan helyzetekben akár finomhangolás nélkül megfelelően működjön, amennyiben a környezeti reprezentáció megfelelő. Másként fogalmazva képes általánosítani a korábban nem látott szituációk esetén is. Ha tehát a példa kedvéért egy autópályás terelésnél megadjuk a szűkített sávok tényét és paramétereit, azokat már akár önállóan felismeri a sárga felfestés alapján.
Hol és hogyan?
Jelenleg három csapat dolgozik ezen a projekten a Budapesti Fejlesztési Központban. A „data-csapat” a források tárolásáért és eléréséért felel, a „blockage-csapat” a kameraszennyeződés felismeréséért felelős és a „behavior prediction” alakulat, akik a viselkedés előjelzését végzik.
Ezek a budapesti mérnökök német, amerikai és angol kollégákkal, valamint telephelyekkel dolgoznak együtt. A tesztjárművek pedig Sunnyvale és Stuttgart környékén járják az utakat. Az útvonalakat megoldandó feladatok alapján tervezik a mérnökök. Például, ha egy szabálytalanul parkoló autó felismerése a cél, akkor olyan kis utcákat választanak, ahol gyakran parkolnak az úton, vagy félig az útra lógó autók.

A budapesti mérnökök többek között a kaliforniai kollégáikkal fejlesztik a rendszert
Az adatokat is az ember rendezi
A tanításhoz használt adatokat kézzel címkézik a kollégák, vagyis az előbb említett parkolási példánál maradva, jelenetenként minden autóról egy ember határozza meg, hogy az épp parkol-e, vagy sem. Ez alapján tanul a modell, illetve a kiértékelésnél is ez a kézi címke segít: ha a modell parkolót mondott, de a címke alapján nem az, akkor fals pozitív, ha fordítva, akkor fals negatív.
Az adatokat balanszolják a mérnökök, vagyis nem mindent használnak fel a tanítás során. A problémás jeleneteket viszont mesterségesen felülreprezentálják. Ez szinte minden önvezető rendszer fejlesztésénél így van. Egyszerűen azért, mert a jelenetek nagy része, 90-95 százalékban megoldható algoritmusokkal. A tanító adatban ezt a kialakult helyzetet szeretnénk kompenzálni. A feltevés itt az, hogy ezeket az egyszerű jeleneteket kevesebb adat alapján is megtanulja. A balanszolás történhet kézi címkézés alapján, vagy teljesen adatvezérelt módon. A kézi esetre példa, ha olyan jeleneteket keresünk, ahol az autók több mint fele parkol. Az adatvezérelt esetben viszont olyan jeleneteket válogatunk be, ahol közel áll egy autó egy közlekedési lámpához, tehát nem parkol, hanem zöld jelzésre vár.

Az adatok értelmezése és feldolgozása továbbra is emberek segítségével történik, ez egy komoly biztonsági funkció is egyben
A módszer használatához több adatforrás (kamera, radar, lidar, ultrahang érzékelő) is felhasználható, ugyanakkor a kamera az egyetlen, ami elengedhetetlen. Ez persze nem csoda, hiszen a rendszer a vizuális adatok feldolgozásán alapul.
A világ minden részén működik
Jogosan merül fel a kérdés: miért vannak tesztjárművek Európában és az Egyesült Államokban is? Bár vannak eltérések a működésben, az ok igazából nem az, hogy különböznek a közlekedési kultúrák, vagy épp a szabályok. Épp ellenkezőleg, a modell általánosan használható a világ szinte minden részén. Ezzel együtt képes kezelni a speciális helyzeteket is. Kiváló példa erre az Egyesült Államokban jellemző szabály, ami szerint piros jelzésnél is kanyarodhatunk jobbra kis ívben, ha a forgalmi körülmények megengedik azt. Ez egy olyan tényező, ami nehézzé teszi annak a megállapítását, hogy a lámpa előtt álló autó akadály vagy releváns várakozó. Az új modell finomhangolásokkal, akár ennek a speciális helyzetnek a kezelésében is jól teljesít.

Az emberi tényező kiszámíthatatlansága jelenleg a legnagyobb kockázati tényező az önvezető rendszereknél. Ennek feldolgozásában segíthet az új módszer
Az új megközelítés tehát segíthet megoldani azokat a szituációkat, amelyeket az eddigi fejlesztési módszerek nem tudtak. Ezen dolgoznak budapesti mérnökeink, szorosan együttműködve a Bosch csoport németországi, angliai és amerikai telephelyeken tevékenykedő kollégáival. A jövő önvezető autóiban ez a tudás adja a biztonságot, a kényelmet és a megbízhatóságot és jó érzés, hogy ehhez mi, Budapestről is hozzájárulhatunk.


