
Ma már gyakran hallani gépi tanulással (machine learning, ML) és mesterséges intelligencia (artificial intellingence, AI) használatával készülő termékekről, vagy épp arról, hogy hogyan segítik ezek a gyártást, a selejtek számának csökkentését, a hibák korai detektálását, vagy más bonyolult folyamatokat. Az azonban koránt sem biztos, hogy maga az algoritmus a kezünkben vagy közvetlen környezetünkben van a használat közben. Ellentmondás lenne ez? Nem, azt is elmagyarázzuk, hogy miért.
- Mit is értünk az alatt, hogy egy problémát a mesterséges intelligencia segítségével szeretnénk megoldani?
- Mit jelent ez a gyakorlatban a rendszer tervezői és fejlesztői számára?
- Milyen lépésekből és problémákból áll össze egy gépi tanulás projekt az elejétől a végéig?
Gyakran szembesülünk olyan téves elképzelésekkel, amelyek szerint, a gépi tanulással készült modell megalkotása egyetlen nagy feladat, amelyért az adattudós kollégák felelnek. A többi járulékos feladatról sokan megfeledkeznek. Pedig ezek teszik ki a munka és az idő túlnyomó részét. Ezek között jellemzően hagyományos értelemben vett szoftverfejlesztési feladatok találhatók, természetesen néhány speciális vonással fűszerezve. A magyarázathoz egy konkrét példát használunk fel.

Egyszerű kérdés, bonyolult válasz
A gépi tanulást használó rendszerek alaptézise, hogy egy probléma esetén egyszerűbb válaszolni a „mit csináljon a rendszer” kérdésre, mint a „hogyan csinálja a rendszer” felvetésre.
Könnyebb tehát olyan példákat (adatokat) keresni, amik leírják, hogy mit csináljon a rendszer (avagy milyen választ, kimenetet várunk el tőle az adott helyzetben), mint tervezni egy bonyolult, sok szabállyal és paraméterrel bíró szoftvert, amelyben pontosan leírjuk, hogyan történjen a feladat megoldása. Csakhogy ebben az esetben a szoftverfejlesztők részéről sokkal nagyobb kreativitásra van szükség.
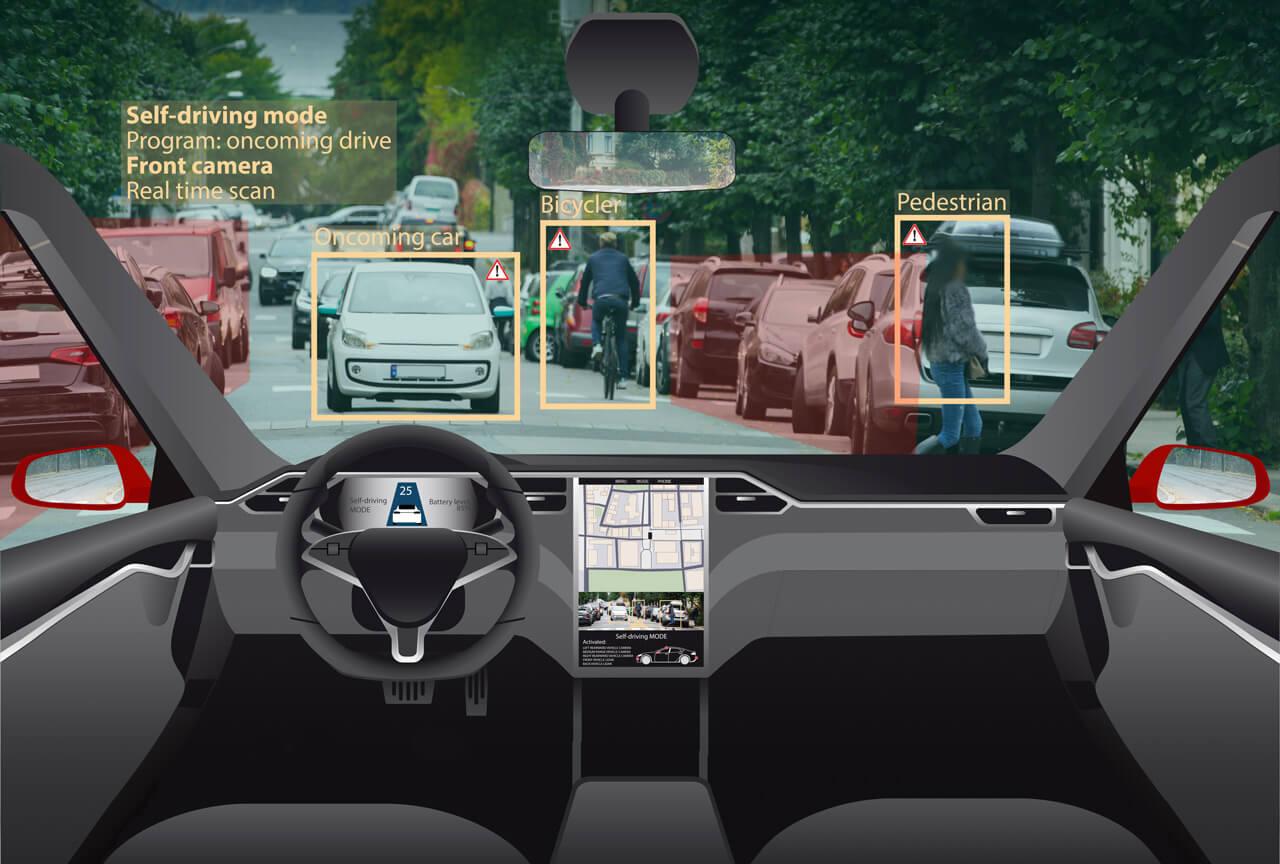
A gyalogosok detektálása minden esetben komoly kihívás, de speciális elvárások esetén különösen bonyolult lehet
Vegyük a már említett konkrét példát: egy jármű esetében a keresztirányból bemozgó gyalogosok felismerése menet közben, egy kamera képei alapján. A rendszer megrendelői kikötötték, hogy az autótól távolodó (a képből kifelé mozgó) gyalogosokat nem kell detektálni, illetve a fejlesztők kaptak egy listát azokról az extra esetekről, ahol szintén nem volt szükséges az észlelés. A probléma pontos megfogalmazása (szabályokkal való leírása, definiálása) ezekkel az extra igényekkel igen nehézzé vált, ezért merült fel a gépi tanulás használata.
A fejlesztői csapat felépítése a klasszikus szoftverfejlesztés kapcsán a hagyományos struktúrára hasonlít. 3-8 fő dolgozik egy-egy modulon. A probléma megértése, az adatok előkészítése a munka körülbelül 70 százalékot jelenti időben, a modellfejlesztés és a tanítás 20 százalékot, az eredmények kiértékelése pedig 10 százalékot tesz ki.
A fejlesztő csapat a lehetséges helyzeteket végiggondolva méréseket végzett, ahol szimuláltak olyan eseteket, ahol szükséges a gyalogos felismerése, és rögzítettek olyan eseteket is, ahol nem. Ezen méréseket később feldolgozták, rendszerbe szervezték és olyan formára alakították, hogy a tanulásra képes rendszer fel tudja használni azokat. Kollégáink a méréseket ellátták egy „detekció szükséges”, illetve egy „detekció nem szükséges” címkével, attól függően, hogy melyik kategóriába tartoztak. Természetesen olyan mérések is készültek, amelyeket a tanulás során nem használtak, ezek segítségével mérhetővé vált a rendszer teljesítménye mind a két kategória kapcsán.
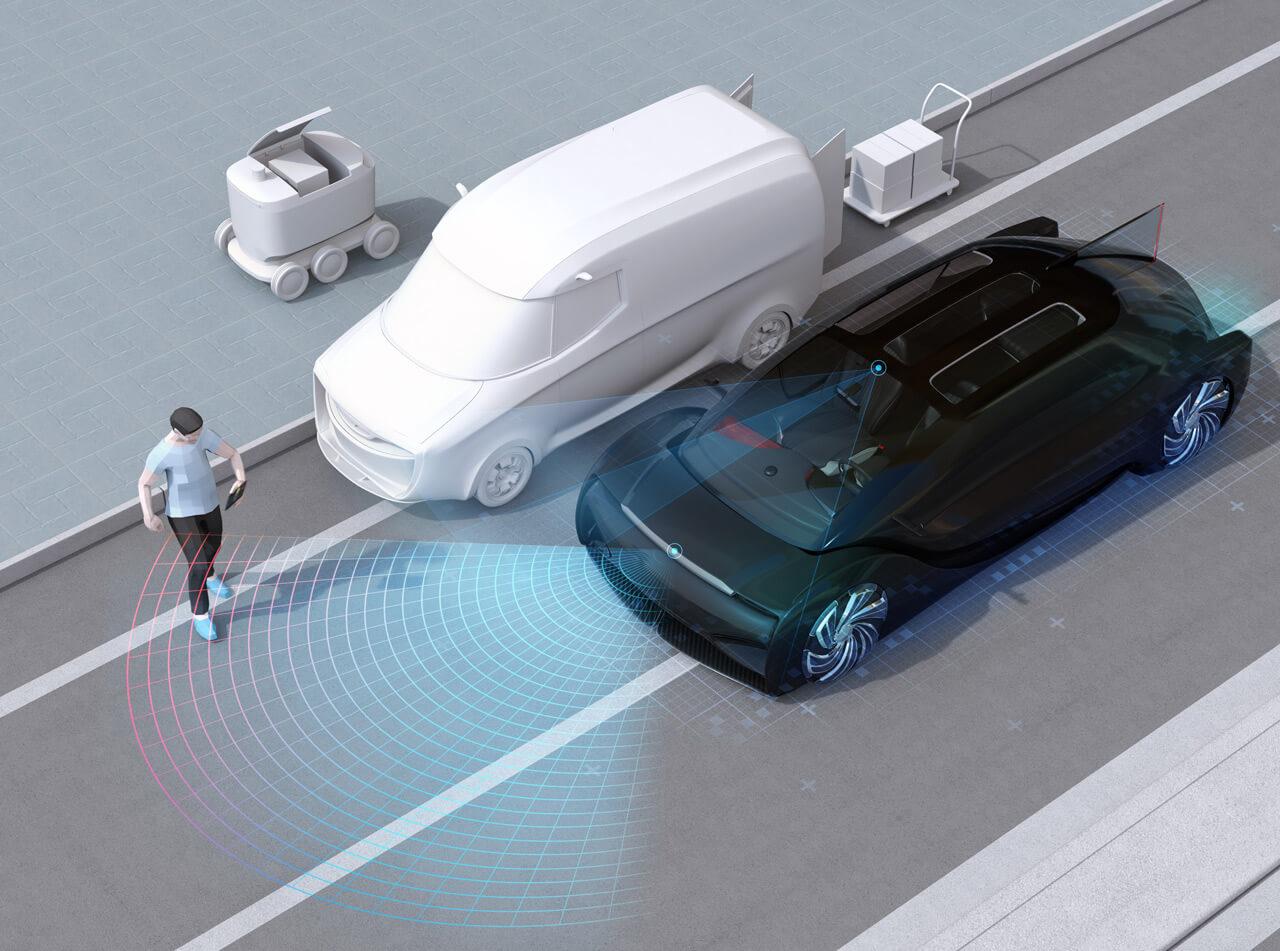
A projekt kapcsán egyáltalán nem volt mindegy, hogy jön vagy megy az a bizonyos gyalogos
Az ilyen gépi tanulás alapú rendszerek is képesek hibázni, ha a készítés/tanítás időszakában használt adatoktól teljesen eltérő körülményekkel találkoznak a valóságban. Az érdekes kérdések ezért ebben a konkrét esetben a következők voltak:
- Mennyi és milyen adatra van szükség a fejlesztéshez?
- Hogyan biztosítjuk, hogy a tanuló rendszer a probléma minden szóba jöhető változatával találkozzon?
- Hogyan tudjuk pontosan mérni a teljesítményt?
Nem helyettünk, velünk dolgozik az MI
A gépi tanuló rendszerek fejlesztésével kapcsolatban elterjedt egy olyan vélekedés, hogy a szoftverfejlesztők munkáját idővel átveszi a mesterséges intelligencia. Állítják ezt sokan azért, mert szerintük ebben a felállásban nincs szükség arra, hogy bonyolult programokat készítsünk, ami a fentebb említett „hogyan csinálja a rendszer” kérdést válaszolja meg. Ez a megállapítás azonban így finoman szólva sem pontos, hiszen az ilyen rendszerek esetében is rengeteg szoftverfejlesztési feladat adódik. Igaz viszont, hogy ezek többnyire más jellegűek: a tanítás során használt adatok feldolgozása, rendszererezése, illetve a folyamat minél hatékonyabbá tétele. Külön problémakör a beágyazott rendszerekben való alkalmazhatóság, hiszen itt is rengeteg szoftverfejlesztéshez kapcsolódó problémán dolgoznak a szakemberek.

Az algoritmusok tanítása kapcsán rengeteg klasszikus programozói feladat is van
Azt gondolhatjuk, hogy ha megvan az algoritmus, az emberi feladat tulajdonképp véget is ér. Ez azonban nem feltétlenül van így. A megrendelő és a fejlesztési csapat pontosan rögzíti mi az elvárt cél. Előbbi biztosítja a szempontrendszert is, ami segítségével ellenőrizni lehet a működést. Mi a Boschnál általában speciális eljárásokkal biztosítjuk a robusztus és biztonságos működést. Ez utóbbi ezekben a speciális helyzetekben sokkal nagyobb kihívás, mint egy klasszikus szoftver esetében.
A gép tanulás esetében az adat az egész fejlesztés mozgatórugója. A gyors előrehaladás érdekében jellemzően a következő igények merülnek fel az adattudósok részéről, akik a modelleket tökéletesítik:
- Legyen sok adat.
- Legyen sokféle az adat.
- Legyen rendszerezett az adat, hogy könnyen megtaláljuk az éppen szükségeset közülük (például az összes olyan adatot, ahol egyszerre van a képbe bemozgó és abból kimozduló gyalogos).
- Legyen gyorsan elérhető az adat.
- Lehessen különböző újra felhasználható adathalmazokat létrehozni, amelyekkel reprodukálhatóvá válnak az eredmények.
- Lehessen követni, hogy melyik adat felvétel milyen módon lett rögzítve, milyen kamerával, milyen szoftver verzióval (hiszen lehetséges, hogy időközben a gyártó lecserélte a kamerát és az új képe kicsit máshogy torzít, vagy csak a képrögzítő szoftveren fejlesztettek menet közben és ez okoz némi változást a képeken).
Látható, hogy a legtöbb esetben valamilyen adatbázis jellegű megoldásra lesz szükségünk, ami számon tudja tartani milyen információink vannak és ezeket rendszerezhetjük benne.

Az adatok feldolgozása és rendszerezése egyáltalán nem egyszerű feladat
Egy másik fontos lépés, ami szintén hagyományos szoftverfejlesztési feladat, az adatok előfeldolgozása. A példánknál maradva ez jelentheti a képek átméretezését, kontrasztjának megváltoztatását, szűrését és még sok más paraméter megváltoztatását. Az előfeldolgozásra azért van szükség, hogy passzoljanak a gépi tanulás modell elvárásaihoz. Ha például egy modellt 100×100 pixeles képekhez optimalizáltak, akkor 640×480 pixeles képekkel nem boldogul majd, így ki kell vágnunk belőle a megfelelő részletet.
Egy járműgyártónál gyakran előfordul, hogy a szoftveres háttér ugyan egyforma, de hardveresen a különböző típusokban eltérés van. A Bosch egyik erőssége pont az, hogy szoftveres és hardveres oldalról is megvannak a szakemberek, így az optimalizáció teljes folyamata megoldható házon belül.
Még közel sem vagyunk készen
Szintén érdekes kérdés, hogy mi történik azokkal az modellekkel, amelyek „tanítása” elkészült. Hol tároljuk ezeket? Megint gondoljunk arra, mire is van szüksége az adattudósoknak. Ha elkészül egy modell, akkor első sorban arra vagyunk kíváncsiak, hogy az mennyire jó. Tehát kell egy szoftver, ami ki tudja értékelni a modell működését a tesztelésre szánt adatok felhasználásával. Egyetlen modell eredménye viszont önmagában nem mond sokat, sokkal izgalmasabb, ha az új modell eredményét egyből össze is tudjuk hasonlítani a tegnapi, az egy héttel, egy hónappal, vagy egy évvel ezelőtti modellek eredményeivel. Tehát szükségünk lesz itt is (az adatokhoz hasonlóan) valamiféle strukturált tárolóra ahová fel tudjuk tölteni azokat és a hozzájuk tartozó tesztek eredményét. Ez megint csak egy újabb hagyományos értelemben vett szoftverfejlesztési feladat.

Az adattudósok és a programozók munkája végül szorosan összekapcsolódik
Fontos megemlíteni azt is, hogy a legtöbb esetben ezek a modellek valamilyen speciális céleszközön futnak, például jelen esetben autókban, de lehet az akár egy porszívó, vagy egy okoslámpa vezérlője is. Ezek hardveres háttere nagyon más, mint a fejlesztői számítógépeké. Így amikor sokan már azt gondolnák, hogy az algoritmus kész, akkor valójában csak egy hosszú folyamat legelső lépésén vagyunk túl. A következő kihívás az, hogy készíteni kell egy szoftvert, ami ezt át tudja konvertálni a céleszközön futtatható „programmá”. Ezután a célhardveren futó modellt valós körülmények között is tesztelni kell, kiértékelni, ami újabb klasszikus szoftverfejlesztési feladatot jelent.
És ez még mindig nem a teljes kép. Egy idő után, ha már sok modell és adat kapcsolódik a projekthez, általában felmerül az igény: a rögzített adatok előfeldolgozását, illetve kiértékelését ne kelljen kézzel futtatni, amikor új adat érkezik. Az elkészült modellek automatikusan dolgozzanak a tesztadatokon és a felhasználónak „csupán” az automatikusan generált riportokat kelljen átnéznie és levonnia a következtetéseket. Ha pedig készül egy új jobb modell, akkor azt egyetlen kattintással lehessen a céleszközre küldeni, ezzel lecserélve az előző verziót. Mindez azt is jelenti, hogy (lehetőleg) felhőben futó, automatizált adatgenerálást, modell kiértékelést, riportgenerálást, valamint modellkonverziót és frissítést kell használni, illetve fejleszteni. Ezek végül összekötik a lépéseket egy nagy folyamattá. Így az adattudós már ténylegesen foglalkozhat a mesterséges intelligencia fejlesztésével.

Összeszokott csapat munkája ez, adattudósok és mérnökök kemény munkájából születnek a mesterséges intelligenciát használó megoldások
Látható, hogy mennyi előkészületre, utómunkára és milyen szoftverkörnyezetre van szükség egyetlen gépi tanulás modell fejlesztési ciklusánál. Ezek kialakítása teszi ki a munka legnagyobb részét.
Egy ilyen elkészült MI fejlesztői környezetből ugyan sok elem és szaktudás újrahasznosítható később más projekteknél is, viszont ez sosem egy egyszerű „másol-beilleszt” folyamat. A szoftverkörnyezet felállítása és karbantartása mindig a teljes munkacsomag nagyobb részét jelenti majd. Az arány természetesen idővel javítható, ahogyan egyre érettebb mesterséges intelligencia fejlesztői környezet alakul ki egy cégnél. Kezdetben ez az arány 95-5 százalék is lehet, ideálisnak már egy 50-50 százalékos arányt tekinthetünk.
A Bosch Budapesti Fejlesztési Központjában közel 50 kolléga dolgozik már MI-projekteken és még 50 másik mérnök az ezekhez kapcsolódó egyéb munkákon (adatelőkészítés, címkézés, kiértékelés, stb.). Ugyanakkor érdekes adat, hogy becslésünk szerint ma már a szoftverekkel foglalkozó kollégák 10-15 százaléka érintett valamilyen szinten mesterséges intelligencia fejlesztésben. Ez az arány még három éve is csak 1-2 százalék volt.
Fontos azonban kiemelni, hogy maga a tanuló algoritmus nem feltétlenül jut el a megrendelőhöz, vagy a végfelhasználóhoz. Általában a hardverek már a kész szoftvert futtatják és csupán a különböző verziókkal frissülnek. Attól tehát nem kell tartani, hogy az autó kamerájához kapcsolódó mesterséges intelligencia tudatára ébred és átveszi az irányítást…

A mesterséges intelligencia terület (jelenleg) kevésbé egzakt, a kreativitásnak nagyobb a szerepe. Ez jó is, és rossz is egyben. Egy MI-projekt sokkal rizikósabb, ezt mutatja az iparági átlag is, amely szerint az ilyen kísérleti projektek 90 százaléka ma még kudarc. Ugyanakkor az is igaz, hogy a potenciális eredmény is könnyebben túlmutathat a kezdeti várakozásokon. Egy alap megoldást elérve, a továbbfejlesztés, vagy optimalizáció teljesen mást jelent, mert ezekben az esetekben már sokkal több generált, vagyis nem emberek által megírt programkód van.


